OpenAI have just released the new GPT-4 Turbo model; there is a substantial list of improvements over plain GPT-4, including a 128K token context window, a maximum reply length extended to 4K tokens, and, not least, a more than two-fold reduction in the cost of making API calls. It seemed crazy not to try it out. After discussing options with the AI, we decided that the right way to incorporate it into C-LARA was to add a configuration screen which lets the user choose both the GPT model and the maximum number of tokens to send to single annotation operations. It looks like this:
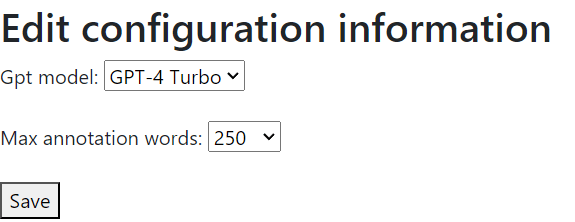
I have been running some initial experiments, using the English examples from our upcoming ALTA paper; I decided to focus on the glossing operation, since that was the one that GPT-4 was having most trouble with in English. So far I’ve only tried a handful of examples, but on those I found that switching from GPT-4 to GPT-4 Turbo reduced the error rate from high teens to mid single digits; then changing ‘Max annotation words’ from 100 to 250 further reduced it to low single digits. However, a further increase of ‘Max annotation words’ to 1000 appeared to overshoot, with error rates rising again for unobvious reasons.
Evidently, more experimentation is needed, but this seems very promising. If you have an account on either Heroku or the new UniSA C-LARA platform, feel free to log in and see what happens in your language of choice!

Leave a comment