We have several parallel discussions in progress about the phonetic texts. I thought it would be helpful to summarise where we are now, and what we’re planning to do next.
By “phonetic text”, we mean a C-LARA text where the words have been divided into smaller units, each one associated with a phonetic value, and something useful happens when you click on a phonetic unit. For example, C-LARA might play the relevant audio or show a concordance of words containing that phonetic value.
If you haven’t yet seen a C-LARA phonetic text, start by taking a look at the alphabet book for Drehu that Pauline and I are putting together. Click and hover to see what happens.
Current functionality
- We can create phonetic texts in two ways. For languages with consistent grapheme-phoneme correspondences (e.g. Arabic, Hebrew, Drehu), you can define a table which maps grapheme-groups to phoneme-groups. For languages with complex and/or inconsistent correspondences where a phonetic lexicon is available (e.g. English, French), you can upload the lexicon and then use an example-based alignment method.
- Data for both methods is uploaded through the ‘Edit phonetic lexicon’ view. Access is limited to people defined as a ‘Language Master’ for the relevant language. If you want to be given Language Master privileges, let me know.
- We currently have “conversion table” data installed for Drehu and Barngarla, “phonetic lexicon” data installed for English, French, Romanian, Icelandic and Dutch. For these languages, you can create phonetic texts using the “Create/edit phonetic text” view and render than using the “Render phonetic text” view.
- For the phonetic lexicon based languages, two kinds of data are generated that can be reviewed and edited by a Language Master in the ‘Edit phonetic lexicon’ view:
- Guessed phonetic lexicon entries. When a lexicon entry doesn’t exist, C-LARA asks GPT-4 to try and create it.
- Guessed alignments. Using either an existing or a created lexicon entry, C-LARA tries to align the graphemes with the phonemes as well as it can, using previously approved alignments to guide it.
- Here are some examples of guessed phonetic entries for English in a text I just processed now:

Note that the AI has guessed entries for the words “upset” and “lives”, which are both missing from the English phonetic lexicon because they are heteronyms: they are pronounced differently depending on what they mean in context. - Here are some examples of guessed alignments for English, same text:
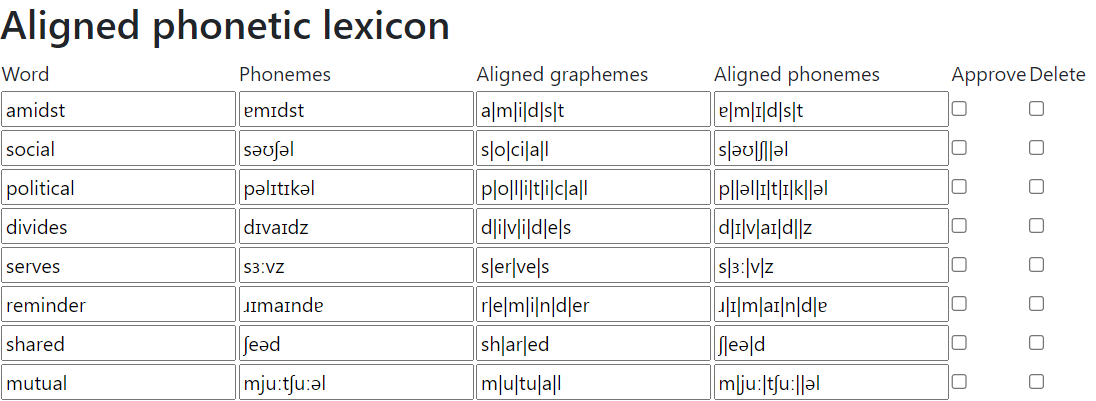
Note that some of the alignments are not optimal. For example, in the second line, “social”, the AI has aligned the final “l” with “əl”, which means that the immediately preceding “a” is aligned with nothing. It would be better to align “a” with “ə” and “l” with “l”. - We can attach audio to grapheme-groups in two ways:
- In any language, we can record human audio manually and upload it. We have done this for Drehu.
- For languages supported by ipa-reader where an IPA-based phonetic lexicon is available, we can automatically create audio from the IPA. However, we find that the audio is sometimes either not produced, or is so quiet that it’s inaudible.
New functionality
We have a bunch of ideas for extending and improving the current functionality:
- Heteronyms. We need to do something about heteronyms, which are common in most languages. Here, we should probably have multiple lexicon entries, one for each pronunciation, and let the AI guess which one to use.
- Presenting guessed lexicon entries. It would be very useful, when reviewing the guessed lexicon entries, to have TTS-generated audio available both for the word and for the generated IPA.
- Improving the alignment process. As you can see, the alignment process does not always seem to be making optimal use of the examples. It may be possible to improve the alignment algorithm, perhaps by tuning the weights for different kinds of grapheme-phoneme alignment.
- Reviewing aligned entries. When we get implausible alignments, this may also be due to having created incorrectly edited/approved examples. It would be useful to be able to retrieve the examples used to justify a given alignment and have the option of editing them.
- Improving the lexicon entry guessing process. I find that the GPT-4 based process for guessing new phonetic lexicon entries needs some tuning of the prompts. For example, in English it was very useful to give it the following advice:
– Note that the English ‘r’ sound is usually represented in IPA as ‘ɹ’.
– Note also that the English hard ‘g’ sound is usually represented in IPA as ‘ɡ’.
Hand-coding this kind of thing is unlikely to be the best approach. It seems possible that we could let GPT-4 tune its own prompts: this would both be useful and theoretically very interesting. - Syllable-based phonetic texts. At the moment, we try to split words into minimal grapheme units, if possible individual letters. It would be useful to give the option of splitting into syllables as well. Again, it seems likely that GPT-4 could perform the syllable-splitting task, perhaps with some language-specific tuning.

Leave a comment